Supervise Finetuning
This experiment is used for supervised fine-tuning (SFT) on UltraChat. This README provides instructions for setting up and running the experiment.
Data Preparation
To begin, you’ll need to obtain the following datasets:
Supervised Fine-Tuning (SFT)
To perform Supervised Fine-Tuning on the UltraChat dataset, use the following script:
export DATA_PATH=data/ultrachat.json
export CONV_TEMPLATE=llama-3-instruct
export MODEL_PATH=pretrained_models/Meta-Llama-3-8B
export GA=16
export OUTPUT_DIR=saved_models/llama-3-8b_ultrachat
bash scripts/train_sft.sh
Sequence Parallel (SP) for Supervised Fine-Tuning (SFT)
We have implemented sequence parallel (SP) for SFT. If you want to use SP, please add these three parameters:
--sequence_parallel_size 8 \
--sequence_parallel_mode "ulysses" \
--cutoff_len 16000
sequence_parallel_size: Used to set the number of GPUs to process a single sequence together. The default value is 1, which means SP is not used.sequence_parallel_mode: Specifies the specific implementation method of SP. We currently only supportulysses.cutoff_len: Used to specify the maximum length that the model can handle.
When using SP, gradient_accumulation_steps needs to be multiplied by sequence_parallel_size to equal the original batch size when not using SP.
Here is the comparison chart of the results with and without sp:
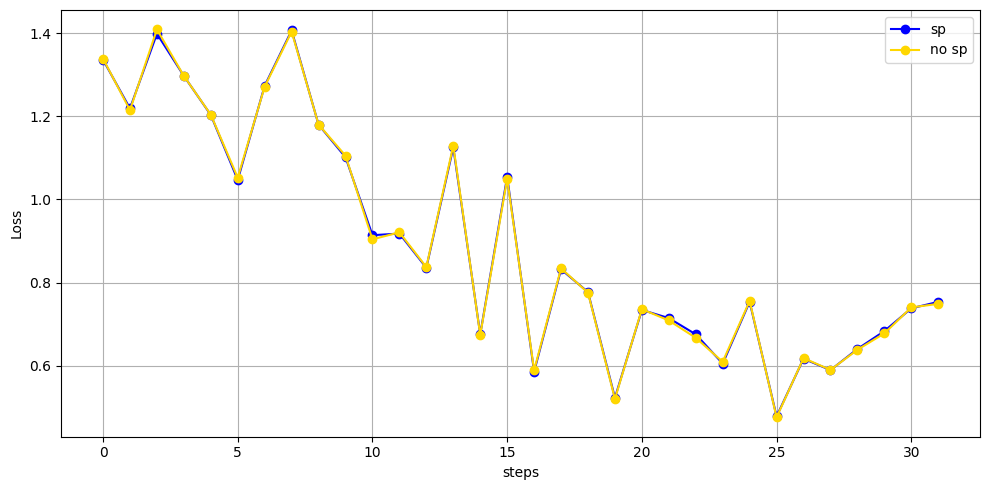
Currently, we have only tested the performance of the Qwen 2.5 and Qwen 3 models on this code, and there have been no issues.
A significant portion of our SP functionality implementation is based on the open-source repository from 360-LLaMA-Factory.
References
@article{ding2023enhancing,
title={Enhancing Chat Language Models by Scaling High-quality Instructional Conversations},
author={Ding, Ning and Chen, Yulin and Xu, Bokai and Qin, Yujia and Zheng, Zhi and Hu, Shengding and Liu, Zhiyuan and Sun, Maosong and Zhou, Bowen},
journal={arXiv preprint arXiv:2305.14233},
year={2023}
}